Original Link: https://www.anandtech.com/show/5458/the-radeon-hd-7970-reprise-pcie-bandwidth-overclocking-and-msaa
The Radeon HD 7970 Reprise: PCIe Bandwidth, Overclocking, & The State Of Anti-Aliasing
by Ryan Smith on January 27, 2012 4:30 PM EST- Posted in
- AMD
- Radeon
- Radeon HD 7000
- GPUs
With the release of AMD’s Radeon HD 7970 it’s clear that AMD has once again regained the single-GPU performance crown. But while the 7970’s place in the current GPU hierarchy is well established, we’re still trying to better understand the ins and outs of AMD’s new Graphics Core Next Architecture. What does it perform well at and what is it weak at? How might GCN scale with future GPUs? Etc.
Next week we’ll be taking a look at CrossFire performance and the performance of AMD’s first driver update. But in the meantime we wanted to examine a few other facets of the 7970: the impact of PCIe bandwidth on performance, overclocking our reference 7970 (and the performance impact thereof), and what AMD is doing for anti-aliasing with the surprise addition of SSAA for DX10+ along with an interesting technical demo implementing MSAA and complex lighting side-by-side. So let’s get started.

PCIe Bandwidth: When Do You Have Enough?
With the release of PCIe 3 we wanted to take a look at what the impact the additional bandwidth would have. Historically new PCIe revisions have come out well ahead of hardware that truly needs the bandwidth, and with the 7970 and PCIe 3 this once again appears to be the case. In our original 7970 review we saw that there were a small number of existing computational applications that could immediately benefit from the greater bandwidth, but what about gaming? We sat down with our benchmark suite and ran it at a number of different PCIe bandwidths in order to find an answer.
| PCIe Bandwidth Comparison (Each Direction) | |||||
| PCIe 1.x | PCIe 2.x | PCIe 3.0 | |||
| x1 | 250MB/sec | 500MB/sec | 1GB/sec | ||
| x2 | 500MB/sec | 1GB/sec | 2GB/sec | ||
| x4 | 1GB/sec | 2GB/sec | 4GB/sec | ||
| x8 | 2GB/sec | 4GB/sec | 8GB/sec | ||
| x16 | 4GB/sec | 8GB/sec | 16GB/sec | ||
For any given game the amount of data sent per frame is largely constant regardless of resolution, so we’ve opted to test everything at 1680x1050. At the higher framerates this resolution offers on our 7970, this should generate more PCie traffic than higher, more GPU limited resolutions, and make the impact of different amounts of PCIe bandwidth more obvious.
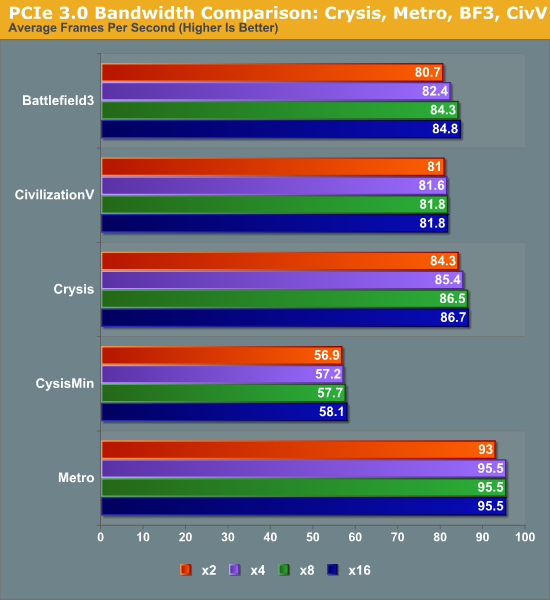
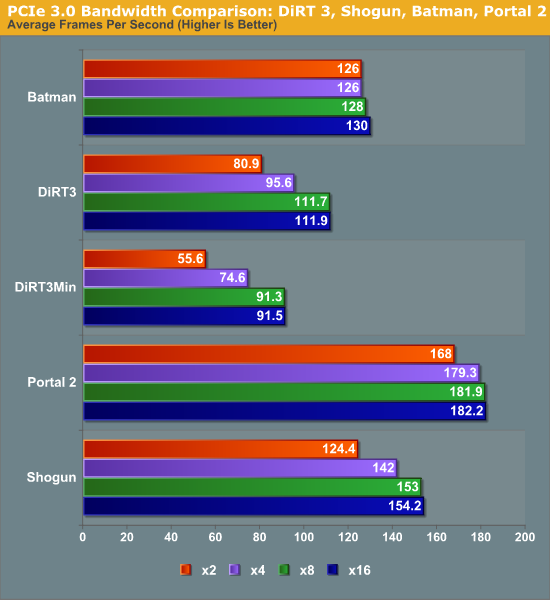
At the high end the results are not surprising. In our informal testing ahead of the 7970 launch we didn’t see any differences between PCIe 2 and PCIe 3 worth noting, and our formal testing backs this up. Under gaming there is absolutely no appreciable difference in performance between PCIe 3 x16 (16GB/sec) and PCIe 2 (8GB/sec). Nor was there any difference between PCIe 3 x8 (8GB/sec) and the other aforementioned bandwidth configurations.
Going forward, for Ivy Bridge owners this will be good news. Even with only 16 PCIe 3 lanes available from the CPU, there should be no performance penalty from utilizing x8 configurations in order to enable CrossFire or other uses that would rob a 7970 of 8 lanes. But how about existing Sandy Bridge systems that can only support PCIe 2? As it turns out things aren’t quite as good.
Moving from PCIe 2 x16 (8GB/sec) to PCIe 2 x8 (4GB/sec) does incur a generally small penalty on the 7970. However like most tests this is entirely dependent on the game itself. With games like Metro 2033 the difference is non-existent, while Battlefield 3 and Crysis only lose 2-3%, and DiRT3 suffers the most, losing 14% of its performance. DiRT3’s minimum framerates look even worse, dropping by 19%. As DiRT3 is one of our higher performing games in the first place the real world difference is not going to be that great – it’s still well above 60fps at all times – but it’s clear that in the wrong situation only having 4GB/sec of PCIe bandwidth can bottleneck a 7970.
Finally if we take one further step to PCIe 3 x2 (2GB/sec), we see performance continue to drop on a game-by-game basis. Crysis, Metro, Civilization V, and Battlefield 3 still hold rather steady, having lost less than 5% of their performance versus PCIe 3 x16, but DiRT 3 continues to fall, while Total War: Shogun and Portal 2 begin to buckle. At these speeds DiRT3 is only 72% of its original performance, while Shogun and Portal 2 are at 81% and 92% respectively.
Ultimately what is clear is that 8GB/sec of bandwidth, either in the form of PCIe 2 x16 or PCIe 3 x8, will be necessary to completely feed the 7970. 16GB/sec (PCIe 3 x16) appears to be overkill for a single card at this time, and 4GB/sec or 2GB/sec will bottleneck the 7970 depending on the game. The good news is that even at 2GB/sec the bottlenecking is rather limited, and based on our selection of benchmarks it looks like a handful of games will be bottlenecked. Still, there’s a good argument here that 7970CF owners are going to want a PCIe 3 system to avoid bottlenecking their cards – in fact this may be the greatest benefit of PCIe 3 right now, as it should provide enough bandwidth to make an x8/x8 configuration every bit as fast as an x16/x16 configuration, allowing for maximum GPU performance with Intel’s mainstream CPUs.
Overclocking Revisited
While we’ve taken a look at overclocking the Radeon HD 7970 in our review of XFX’s Radeon HD 7970 Black Edition Double Dissipation, that was a look at XFX’s custom cooled card. We’ve had a number of requests for overclocking performance on our reference card, so we’ve gone ahead and done that.
In the meantime though a couple interesting facts have come to light. While both our reference card and our XFX card ran at 1.175v, it turns out that this is not the only voltage the 7970 ships at. Retail buyers have reported receiving cards that run at 1.112v and 1.05v, and Alexey Nicolaychuk (aka Unwinder), the author of MSI Afterburner, has discovered that there’s a 4th voltage according to the fuses on Tahiti: 1.025v. 1.025v has not been seen in any retail cards so far, and it’s most likely a bin that’s reserved for future products (e.g. the eventual 7990), while out of the remaining 3 voltages 1.175 appears to be the most common.
| Radeon HD 7900 Series Voltages | ||||
| Ref 7970 Load | Ref 7970 Idle | XFX 7970 Black Edition DD | ||
| 1.17v | 0.85v | 1.17v | ||
In any case, in overclocking our reference 7970 we’ve found that the results are very close to our XFX 7970. Whereas our XFX 7970 could hit 1125MHz without overvolting, our reference 7970 topped out at a flat 1100MHz. Meanwhile our memory speeds reached 6.3GHz before performance began to dip, which was the same point we reached on the XFX 7970 and not at all surprising since both boards use the same PCB.
Overall this represents a 175MHz (18%) core overclock and 800MHz (15%) memory overclock over the stock clocks of our reference 7970. As we’ll see, since this is being done without overvolting the power consumption hit (and all consequences thereof) from this is minimal to non-existent, making this a rather sizable free overclock.
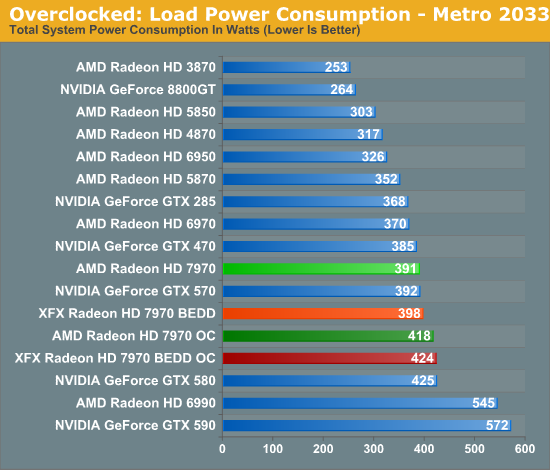
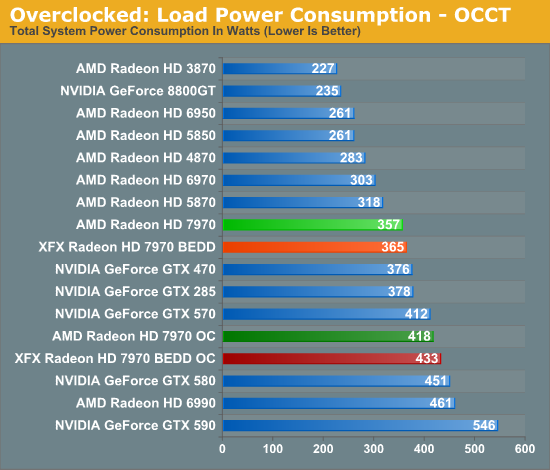
Taking a quick look at power/temp/noise, we see that the increase in load power is consistent with our earlier results with the XFX 7970. Under Metro the power increase is largely the CPU ramping up to feed the now-faster 7970. While under OCCT we’re seeing the consequence of increasing the PowerTune limit so that we don’t inadvertently throttle performance when gaming.
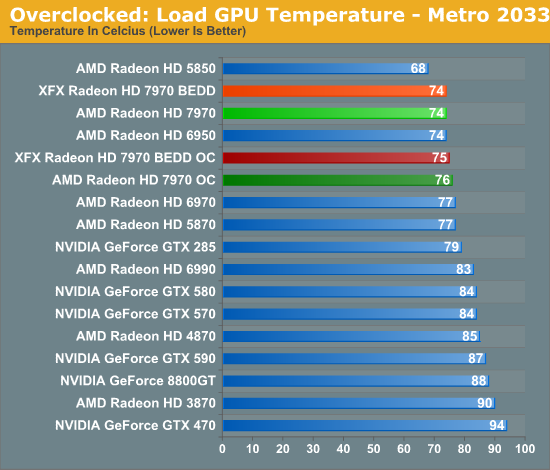
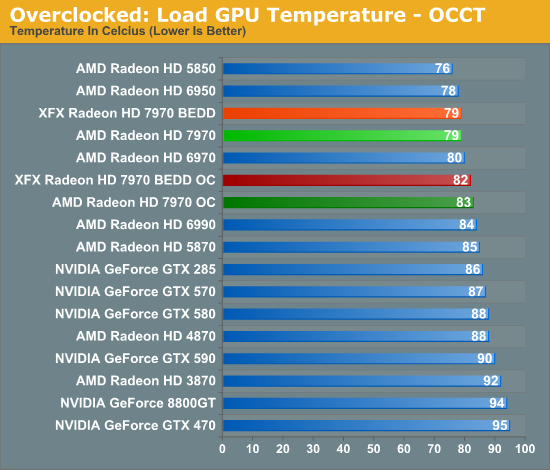
With almost no increase in GPU power consumption while gaming, temperatures hold steady. This translates to a 2C increase in temperatures, while under OCCT the difference is 4C.
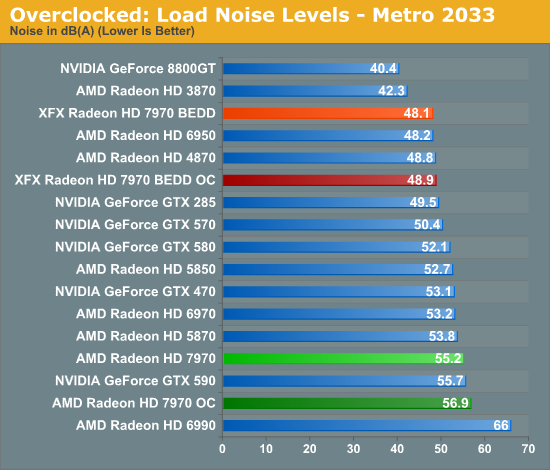
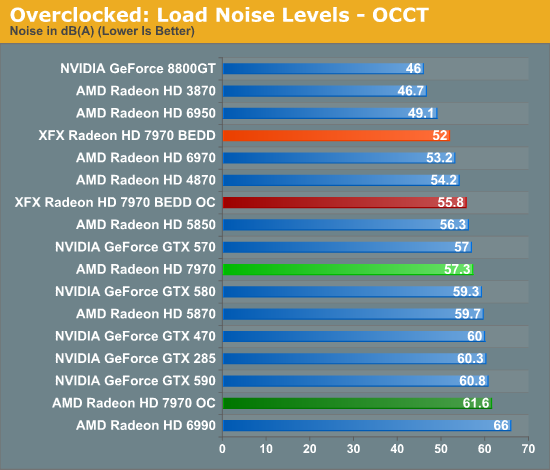
Finally, as with temperature, noise only ever so slightly creeps up. Unfortunately for most users, AMD’s already aggressive fan profile makes this relatively loud card just a bit louder yet; the temperatures are fantastic, but the noise less so. Things look even worse under OCCT, but again this is a pathological test with PowerTune increased to 300W.
Meanwhile gaming performance is where you’d expect it to be for a card with this degree of an overclock. As most tests scale very well with the increase in the core clock virtually all of our games are 15-20% faster over a reference 7970. Whereas compared to the XFX 7970, at 98% of the XFX 7970’s overclock, our overclocked reference 7970 is only a couple percent behind the XFX card and barely outside the margin of error of most tests.
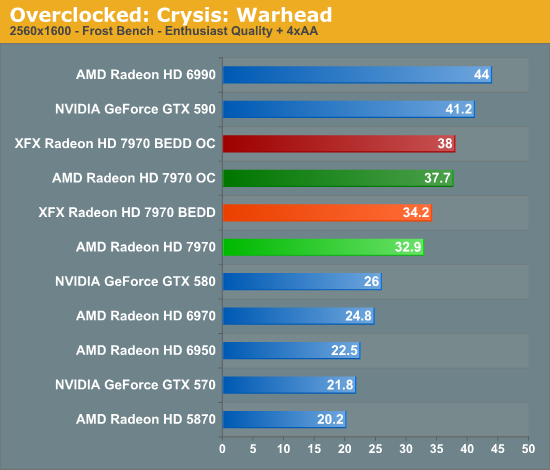
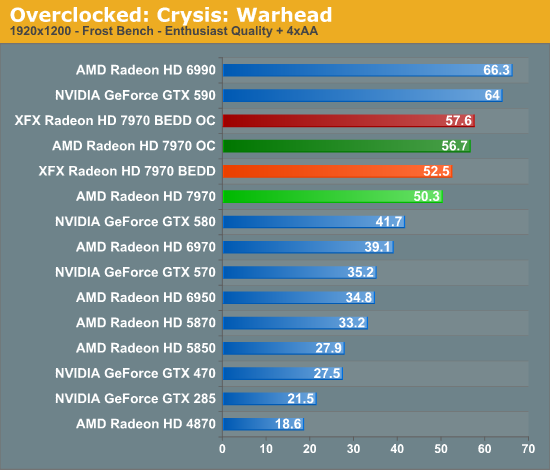
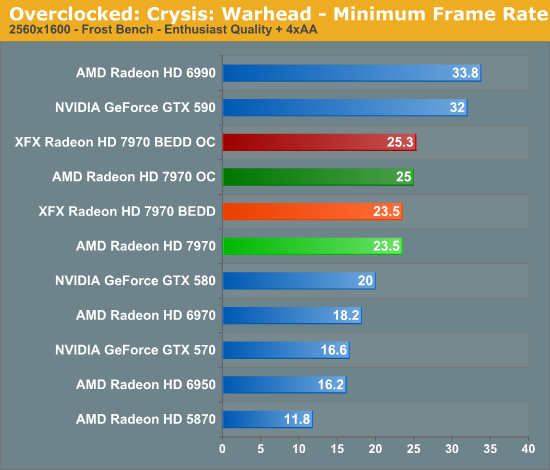

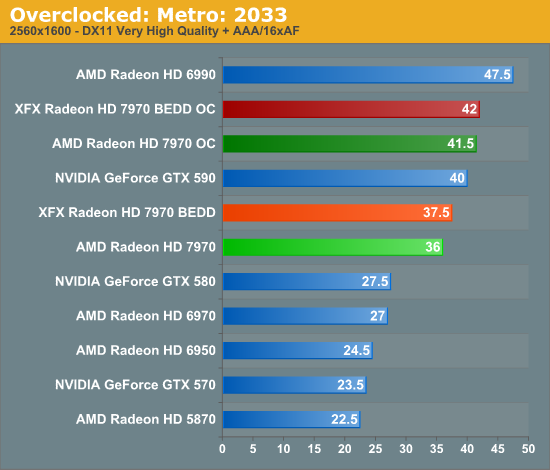
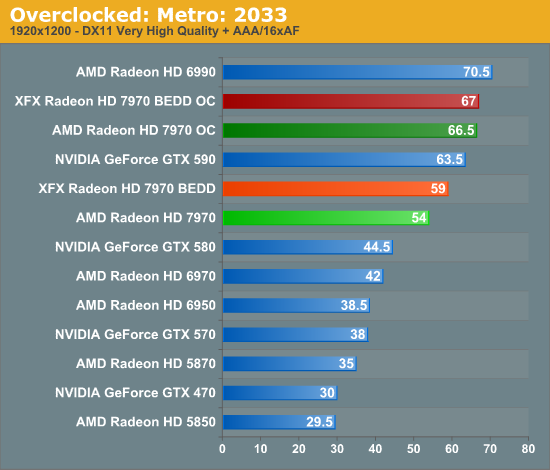
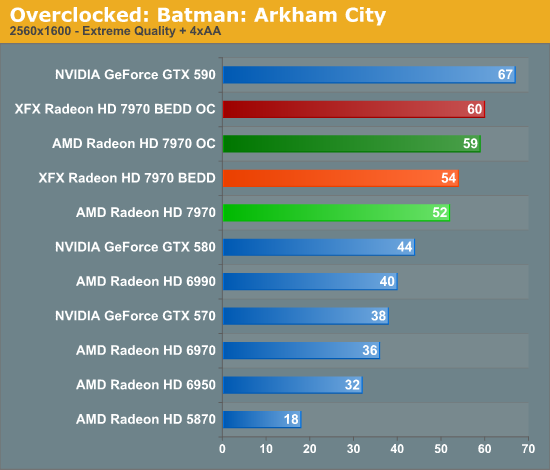
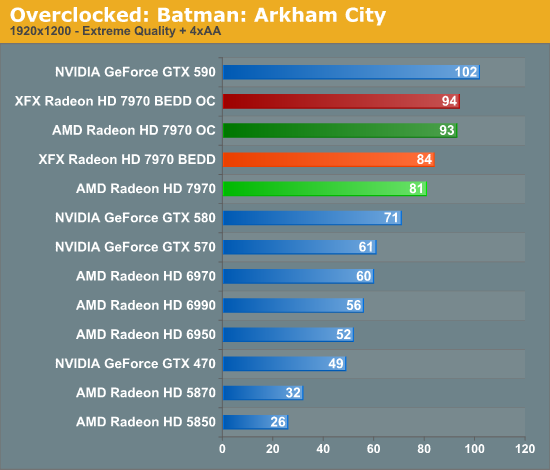
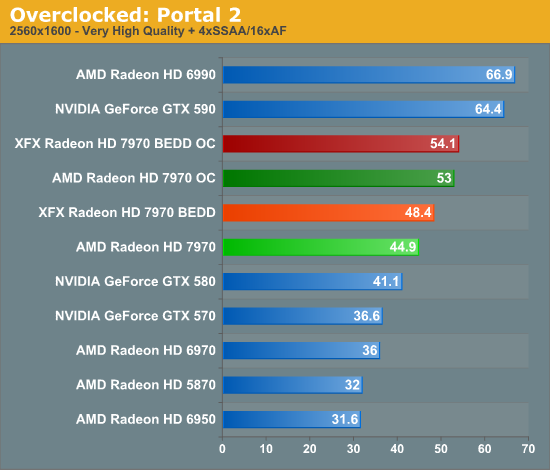
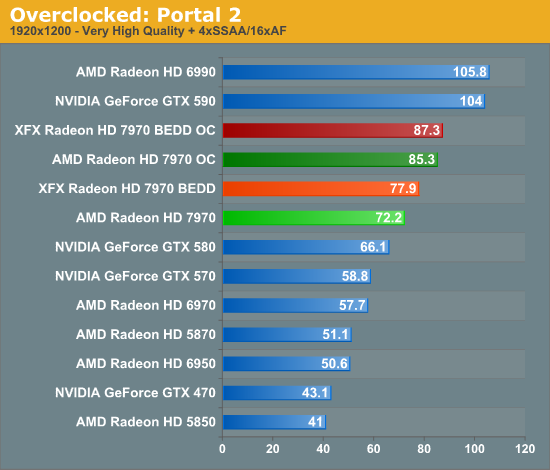
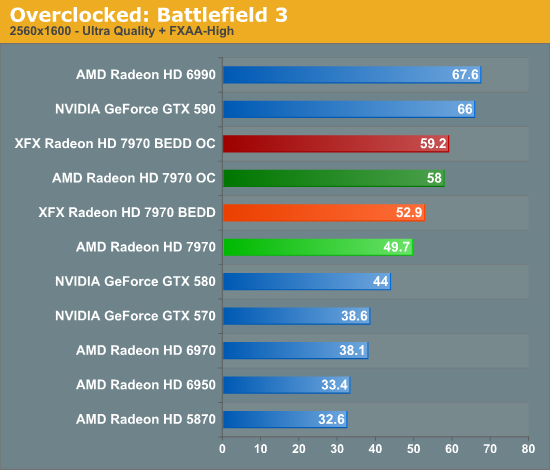
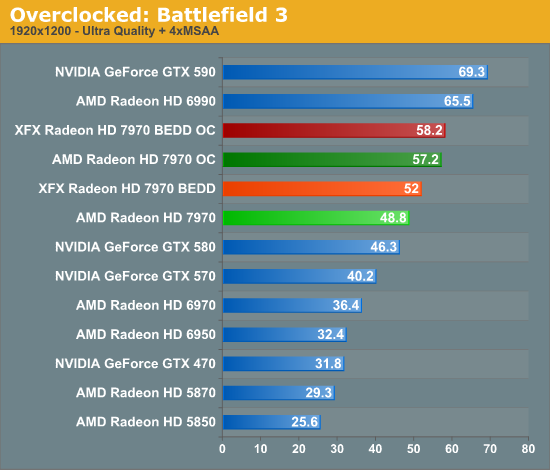
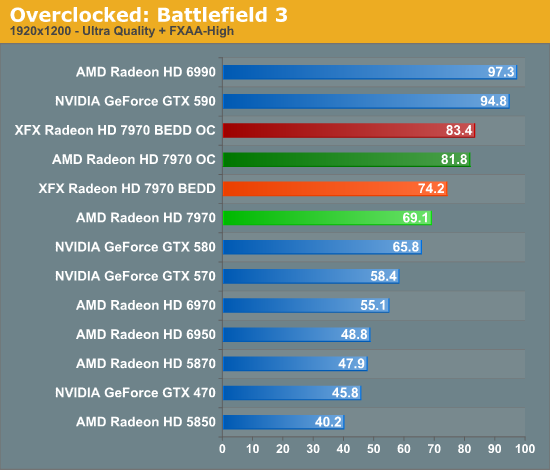


All things considered, outside of warranty restrictions there seems to be very little reason not to overclock the 7970 on its default voltage. Even a conservative overclock of 1050MHz would add 13% to the core clocks (and as a result performance in virtually all GPU-limited scenarios), which is a big enough leap in performance to justify spending the time setting up and testing the overclock. By not raising the core voltage there’s effectively no power/noise tradeoff and this seems to be achievable by virtually every 7970, making this a freebie overclock the likes of which we’re more accustomed to seeing on high-end CPUs than we are flagship GPUs.
Improving the State of Anti-Aliasing: Leo Makes MSAA Happen, SSAA Takes It Up A Notch
As you may recall in our initial review of the 7970, I expressed my bewilderment that AMD had not implemented Adaptive Anti-Aliasing (AAA) and Super Sample Anti-Aliasing (SSAA) for DX10+ in the Radeon HD 7000 series. There has never been a long-term AA mode gap in recent history, and it was AMD who made DX9 SSAA popular again in the first place when they made it a front-and-center feature of the Radeon HD 5000 series. AMD’s response at the time was that they preferred to find a way to have games implement these AA modes natively, which is not an unreasonable position, but an unfortunate one given the challenge in just getting game developers to implement MSAA these days.
So it was with a great deal of surprise and glee on our part that when AMD released their first driver update last week, they added an early version of AAA and SSAA support for DX10+ games. Given their earlier response this was unexpected, and in retrospect either AMD was already working on this at the time (and not ready to announce it), or they’ve managed to do a lot of work in a very short period of time.
As it stands, AMD’s DX10+ AAA/SSAA implementation is still a work in progress, and it will only work on games that natively support MSAA. Given the way the DX10+ rendering pipeline works, this is a practical compromise as it’s generally much easier to implement SSAA after the legwork has already been done to get MSAA working.
We haven’t had a lot of time to play with the new drivers, but in our testing AAA/SSAA do indeed work. A quick check with Crysis: Warhead finds that AMD’s DX10+ SSAA implementation is correctly resolving transparency aliasing and shader aliasing as it should be.

Crysis: Warhead SSAA: Transparent Texture Anti-Aliasing

Crysis: Warhead SSAA: Shader Anti-Aliasing
Of course, if DX10+ SSAA only works with games that already implement MSAA, what does this mean for future games? As we alluded to earlier, built-in MSAA support is not quite prevalent across modern games, and the DX10+ pipeline makes forcing it from the driver side a tricky endeavor at best. One of the biggest technical culprits (as opposed to quickly ported console games) is the increasing use of deferred rendering, which makes MSAA more difficult for developers to implement.
In short, in a traditional (forward) renderer, the rendering process is rather straightforward and geometry data is preserved until the frame is done rendering. And while this normally is all well and good, the one big pitfall of a forward renderer is that complex lighting is very expensive to run because you don’t know precisely which lights will hit which geometry, resulting in the lighting equivalent of overdraw where objects are rendered multiple times to handle all of the lights.
In deferred rendering however, the rendering process is modified, most fundamentally by breaking it down into several additional parts and using an additional intermediate buffer (the G-Buffer) to store the results. Ultimately through deferred rendering it’s possible to decouple lighting from geometry such that the lighting isn’t handled until after the geometry is thrown away, which reduces the amount of time spent calculating lighting as only the visible scene is lit.
The downside to this however is that in its most basic implementation deferred rendering makes MSAA impossible (since the geometry has been thrown out), and it’s difficult to efficiently light complex materials. The MSAA problem in particular can be solved by modifying the algorithm to save the geometry data for later use (a deferred geometry pass), but the consequence is that MSAA implemented in such a manner is more expensive than usual both due to the amount of memory the saved geometry consumes and the extra work required to perform the extra sampling.

Battlefield3 G-Buffer. Image Courtesy DICE
For this reason developers have quickly been adopting post-process AA methods, primarily NVIDIA’s Fast Approximate Anti-Aliasing (FXAA). Similar in execution to AMD’s driver-based Morphological Anti-Aliasing, FXAA works on the fully rendered image and attempts to look for aliasing and blur it out. The results generally aren’t as good as MSAA (and especially not SSAA), but it’s very quick to implement (it’s just a shader program) and has a very small performance hit. Compared to the difficultly of implementing MSAA on a deferred renderer, this is faster and cheaper, and it’s why MSAA support for DX10+ games is anything but universal.

AMD's Leo Tech Demo
But what if there was a way to have a forward renderer with performance similar to that of a deferred renderer? That’s what AMD is proposing with one of their key tech demos for the 7000 series: Leo. Leo showcases AMD’s solution to the forward rendering lighting performance problem, which is to use a compute shader to implement light culling such that the compute shader identifies the tiles that any specific light will hit ahead of time, and then using that information only the relevant lights are computed on any given tile. The overhead for lighting is still greater than pure deferred rendering (there’s still some unnecessary lighting going on), but as proposed by AMD, it should make complex lighting cheap enough that it can be done in a forward renderer.






As AMD puts it, the advantages are twofold. The first advantage of course is that MSAA (and SSAA) compatibility is maintained, as this is still a forward render; the use of the compute shader doesn’t have any impact on the AA process. The second advantage relates to lighting itself: as we mentioned previously, deferred rendering doesn’t work well with complex materials. On the other hand forward rendering handles complex materials well, it just wasn’t fast enough until now.
Leo in turn executes on both of these concepts. Anti-aliasing is of course well represented through the use of 4x MSAA, but so are complex materials. AMD’s theme for Leo is stop motion animation, so a number of different material types are directly lit, including fabric, plastic, cardboard, and skin. The total of these parts may not be the most jaw-dropping thing you’ve ever seen, but the fact that it’s being done in a forward renderer is amazingly impressive. And if this means we can have good lighting and excellent support for real anti-aliasing, we’re all for it.
Unfortunately it’s still not clear at this time when 7970 owners will be able to get their hands on the demo. The version released to the press is still a pre-final version (version number 0.9), so presumably AMD’s demo team is still hammering out the demo before releasing it to the public.
Update: AMD has posted the Leo demo, along with their Ptex demo over at AMD Developer Central. It should work with any DX11 card, though a quick check has it failing on NVIDIA cards






